- Published on
Setup a Distributed Storage Volume with GlusterFS
- Authors

- Name
- Ruan Bekker
- @ruanbekker
GlusterFS is a Awesome Scalable Networked Filesystem, which makes it Easy to Create Large and Scalable Storage Solutions on Commodity Hardware.

Basic Concepts of GlusterFS:
Brick:
- In GlusterFS, a brick is the basic unit of storage, represented by a directory on the server in the trusted storage pool.
Gluster Volume:
- A Gluster volume is a Logical Collection of Bricks.
Distributed Filesystem:
- The concept is to enable multiple clients to concurrently access data which is spread across multple servers in a trusted storage pool. This is also a great solution to prevent data corruption, enable highly available storage systems, etc.
More concepts can be retrieved from their documentation.
Different GlusterFS Volume Types:
With GlusterFS you can create the following types of Gluster Volumes:
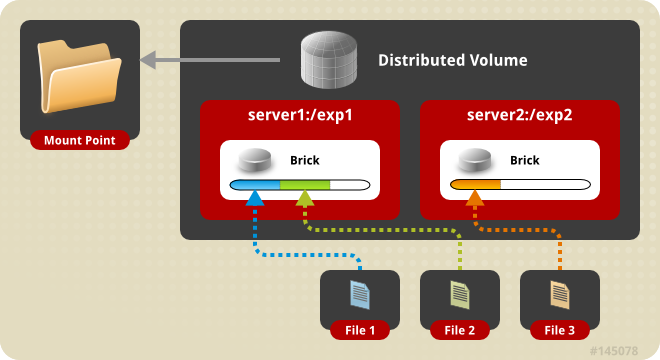
- Distributed Volumes: (Ideal for Scalable Storage, No Data Redundancy)
- Replicated Volumes: (Better reliability and data redundancy)
- Distributed-Replicated Volumes: (HA of Data due to Redundancy and Scaling Storage)
- More detail on GlusterFS Architecture
Setup a Distributed Gluster Volume:
In this guide we will setup a 3 Node Distributed GlusterFS Volume on Ubuntu 16.04.
For this use case we would like to achieve a storage solution to scale the size of our storage, and not really worried about redundancy as, with a Distributed Setup we can increase the size of our volume, the more bricks we add to our GlusterFS Volume.
Setup: Our Environment
Each node has 2 disks, /dev/xvda for the Operating System wich is 20GB and /dev/xvdb which has 100GB. After we have created our GlusterFS Volume, we will have a Gluster Volume of 300GB.
Having a look at our disks:
$ lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
xvda 202:0 0 20G 0 disk
└─xvda1 202:1 0 20G 0 part /
xvdb 202:16 0 100G 0 disk
If you don't have DNS setup for your nodes, you can use your /etc/hosts file for all 3 nodes, which I will be using in this demonstration:
$ cat /etc/hosts
172.31.13.226 gluster-node-1
172.31.9.7 gluster-node-2
172.31.15.34 gluster-node-3
127.0.0.1 localhost
Install GlusterFS from the Package Manager:
Note that all the steps below needs to be performed on all 3 nodes, unless specified otherwise:
$ apt update && apt upgrade -y
$ apt install xfsprogs attr glusterfs-server glusterfs-client glusterfs-common -y
Format and Prepare the Gluster Disks:
We will create a XFS Filesystem for our 100GB disk, create the directory path where we will mount our disk onto, and also load it into /etc/fstab:
$ mkfs.xfs /dev/xvdb
$ mkdir /gluster
$ echo '/dev/xvdb /gluster xfs defaults 0 0' >> /etc/fstab
$ mount -a
After we mounted the disk, we should see that our disk is mounted to /gluster:
$ df -h
Filesystem Size Used Avail Use% Mounted on
/dev/xvda1 20G 1.2G 19G 7% /
/dev/xvdb 100G 33M 100G 1% /gluster
After our disk is mounted, we can proceed by creating the brick directory on our disk that we mounted, from the step above:
$ mkdir /gluster/brick
Start GlusterFS Service:
Enable GlusterFS on startup, start the service and make sure that the service is running:
$ systemctl enable glusterfs-server
$ systemctl restart glusterfs-server
$ systemctl is-active glusterfs-server
active
Discover All the Nodes for our Cluster:
The following will only be done on one of the nodes. First we need to discover our other nodes.
The node that you are currently on, will be discovered by default and only needs the other 2 nodes to be discovered:
$ gluster peer probe gluster-node-2
$ gluster peer probe gluster-node-3
Let's verify this by listing all the nodes in our cluster:
$ gluster pool list
UUID Hostname State
6e02731c-6472-4ea4-bd48-d5dd87150e8b gluster-node-2 Connected
9d4c2605-57ba-49e2-b5da-a970448dc886 gluster-node-3 Connected
608f027e-e953-413b-b370-ce84050a83c9 localhost Connected
Create the Distributed GlusterFS Volume:
We will create a Distributed GlusterFS Volume across 3 nodes, and we will name the volume gfs:
$ gluster volume create gfs \
gluster-node-1:/gluster/brick \
gluster-node-2:/gluster/brick \
gluster-node-3:/gluster/brick
volume create: gfs: success: please start the volume to access data
Start the GlusterFS Volume:
Now start the gfs GlusterFS Volume:
$ gluster volume start gfs
volume start: gfs: success
To get information about the volume:
$ gluster volume info gfs
Volume Name: gfs
Type: Distribute
Volume ID: c08bc2e8-59b3-49e7-bc17-d4bc8d99a92f
Status: Started
Number of Bricks: 3
Transport-type: tcp
Bricks:
Brick1: gluster-node-1:/gluster/brick
Brick2: gluster-node-2:/gluster/brick
Brick3: gluster-node-3:/gluster/brick
Options Reconfigured:
performance.readdir-ahead: on
Status information about our Volume:
$ gluster volume status
Status of volume: gfs
Gluster process TCP Port RDMA Port Online Pid
------------------------------------------------------------------------------
Brick gluster-node-1:/gluster/brick 49152 0 Y 7139
Brick gluster-node-2:/gluster/brick 49152 0 Y 7027
Brick gluster-node-3:/gluster/brick 49152 0 Y 7099
NFS Server on localhost 2049 0 Y 7158
NFS Server on gluster-node-2 2049 0 Y 7046
NFS Server on gluster-node-3 2049 0 Y 7118
Task Status of Volume gfs
------------------------------------------------------------------------------
There are no active volume tasks
Mounting our GlusterFS Volume:
On all the clients, in this case our 3 nodes, load the mount information into /etc/fstab and then mount the GlusterFS Volume:
$ echo 'localhost:/gfs /mnt glusterfs defaults,_netdev,backupvolfile-server=gluster-node-1 0 0' >> /etc/fstab
$ mount -a
Now that the volume is mounted, have a look at your disk info, and you will find that you have a 300GB GlusterFS Volume mounted:
$ df -h
Filesystem Size Used Avail Use% Mounted on
/dev/xvda1 20G 1.3G 19G 7% /
/dev/xvdb 100G 33M 100G 1% /gluster
localhost:/gfs 300G 98M 300G 1% /mnt
As mentioned before, this is most probably for a scenario where you would like to achieve a high storage size and not really concerned about data availability.
In the next couple of weeks I will also go through the Replicated, Distributed-Replicated and GlusterFS with ZFS setups.
Resources:
Thank You
Thanks for reading, feel free to check out my website, and subscribe to my newsletter or follow me at @ruanbekker on Twitter.
- Linktree: https://go.ruan.dev/links
- Patreon: https://go.ruan.dev/patreon
